Accurate prediction of the energy consumption of a building is pivotal to performing optimal energy management, taking advantage of dynamic pricing, and allocation of distributed storage and generation resources (e.g., for demand side management). Several methods exist to forecast the hourly building energy consumption. Majority of the popular forecasting models can be classified into two major types: (1) simulation-based or physical-based methods, and (2) data-driven statistical methods. Another typical classification includes categories known as white box, black box, and gray box models, with the latter involving a combination of physics-based and data-driven models.
However there are some research studies in this area, there are well understood drawbacks to these efforts. The reported ANN based models have been tested mostly on one building with data over a short duration (two seasons at most). It is not clear if the methods are generalizable and adaptive to varying conditions and sensitive to the extent and coverage offered by the training data set. Moreover, previous efforts in the literature generally considered a small set of the weather parameters and the selection of parameters is often not supported with sensitivity analysis (providing insights into their likely impact on the building energy profile).
We are developing one day-ahead hourly energy forecasting framework for buildings using optimally selected surrogate models
and Artificial Neural Network (ANN) models. In doing so , we first develop and present important preprocessing tools that are
needed when dealing with real building data. Optimal model selection takes place through the use of a unique automated surrogate
model selection method and through parametric studies on the ANN topology and configuration. An energy baseline concept is also explore to potentially improve the prediction accuracy and case studies are presented using more than 2-years data from three campus buildings in University at Buffalo (currently we have energy consumption data for 18 buildings of the university).
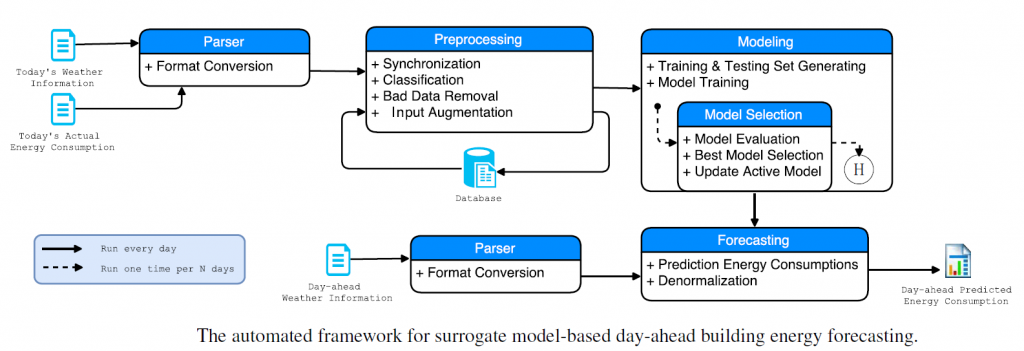
The automated framework to perform data-driven day-ahead forecasting of the hourly energy consumption of a building is a multi-stage computation framework, including: (1) Parser, (2) Preprocessing, (3) Modeling, and (4) Forecasting.
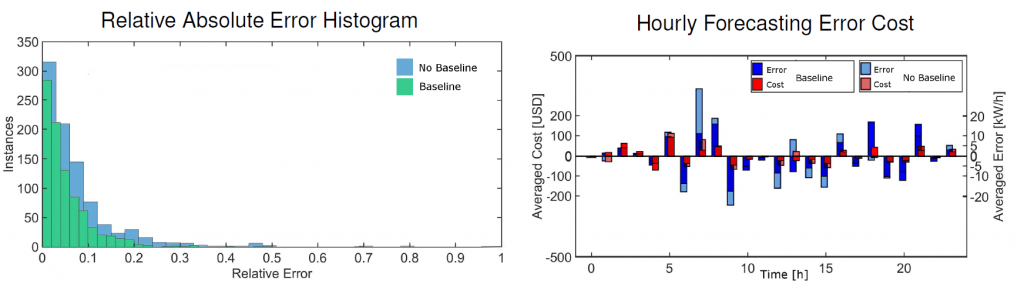
(1) A baseline concept is introduced to improve the performance of the energy consumption predictor, where the average energy consumption of the previous day serves as the baseline, and is used to bias the current predictions towards recent history. The baseline is observed to provide significant improvements in the prediction accuracy. (2) The forecasting errors are scaled with the actual price to illustrate that a higher margin of error might be acceptable during off-peak hours, while lower margin or error is desired during peak hours.
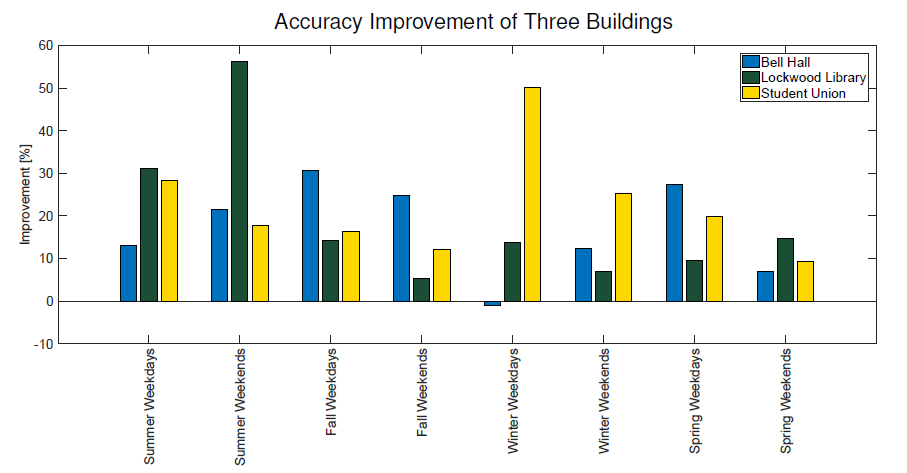
For different building, which has different occupancy and behavior pattern, the baseline improves the accuracy.
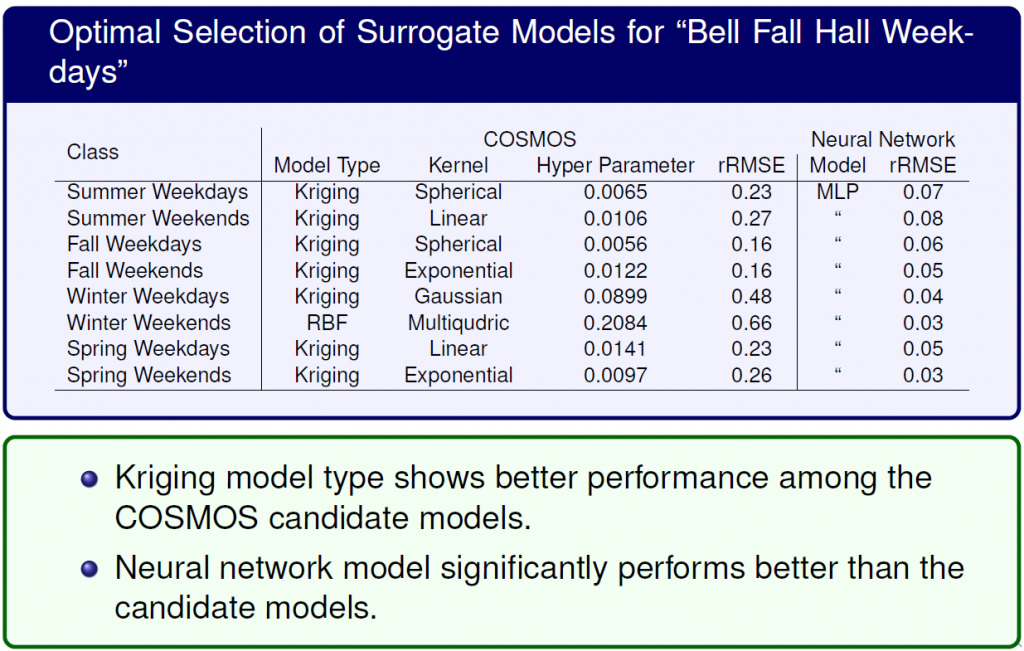
Final performance and parameters of each surrogate model regarding to the given data.